2020 年通过扩展出 bfloat16 加速功能,面向多路服务器的第三代至强可扩展处理器在推理加速能力之外,又增加了训练加速能力,已被证明可以帮助业界大量 AI 工作负载实现更优的性能和功耗比。
就在大家认为英特尔在 CPU 加速 AI 的技术创新和投入会止步于此的时候,第四代至强可扩展芯片,又带来了矩阵化的算力支持 ——AMX。

第四代英特尔至强可扩展处理器
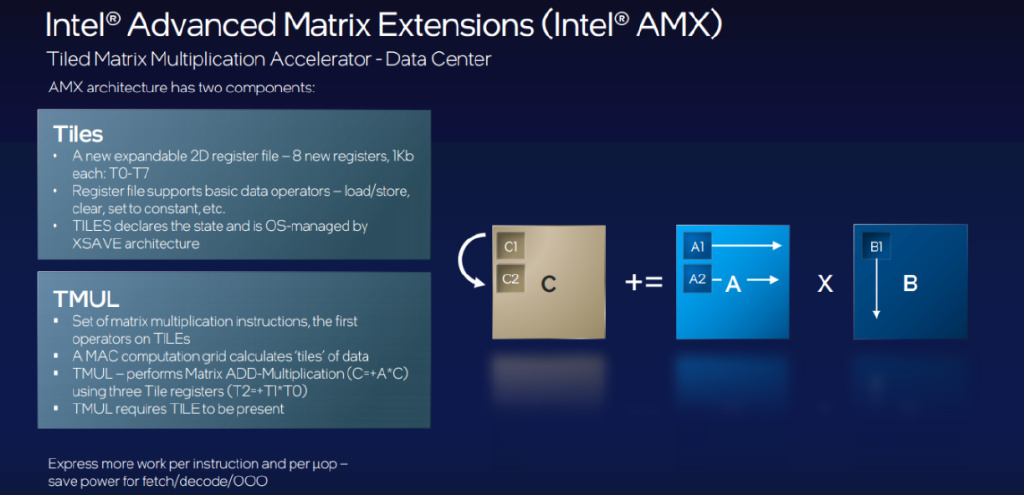
这种全新内置 AI 加速器的出现,进一步验证了「与其增加 CPU 内核数和时钟频率,加入和更新专用计算单元对提升 AI 工作负载性能更有效」这一思路。正如前文所述,第四代至强可扩展芯片不仅可借助 AMX 实现相当于上一代芯片(FP32)10 倍的 AI 性能提升,与前两代产品使用的深度学习加速技术相比,其理论性能(每秒操作量)最高也可以达到其 8 倍之多。
机器学习包含大量的矩阵计算,在主打通用计算的 CPU 上,此类任务会被转换为效率较低的向量计算,而在加入专用的矩阵计算单元后,至强 CPU 的 AI 能力有了巨大的提升。因此,AMX 可以被视为至强 CPU 上的「TensorCore」—— 从原理上看,CPU 上的 AI 加速器实现的目的和 GPU、移动端处理器上的类似。由于 AMX 单元对底层矩阵计算进行加速,理论上它对于所有基于深度学习的 AI 应用都能起到效果。
如果说 AMX 为至强 CPU 带来的是直观的推理和训练加速,那么第四代至强可扩展芯片内置的其他几种加速器,就是为 AI 端到端应用加速带来的惊喜。
这是因为在真正完整的 AI 应用流水线中,任务往往会从数据的处理和准备开始,在这一阶段,第四代至强可扩展芯片内置的数据流加速器(DSA),可让数据存储与传输性能提升到上一代产品的 2 倍,而专门针对数据库和数据分析加速的英特尔存内分析加速器(IAA),也可将相关应用的性能提升到上一代产品的三倍(RocksDB);数据保护与压缩加速技术(QAT),则能在内核用量减少多达 95% 的情况下将一级压缩吞吐量提升至原来的两倍。这些技术的使用,也有助于 AI 端到端应用性能的整体跃升。

此外,随着 AI 应用在更多行业,包括金融、医疗等数据敏感型行业的落地,人们对于数据安全合规的要求逐渐提高,联邦学习等技术逐渐获得应用。在这一方面,至强可扩展处理器集成的专攻数据安全强化的加速器 —— 软件防护扩展(SGX),也是大有用武之地,它的突出优势就是可以为处理中或运行中的敏感数据和应用代码提供与其他系统组件和软件隔离的安全飞地,实现更小的信任边界。
这种技术对于 AI 而言,最核心的价值就是可以让有多方数据交互、协作的 AI 训练过程变得更加安全,各方数据都可以在其拥有者的本地参与训练,用于训练的数据和模型会被安全飞地所保护,最终模型可以在这种保护下提升精度和效率,但为其演进做出了关键贡献的数据则会一直处于「可用而不可见 」的状态下,以确保其中的敏感和隐私信息的安全性。